前端路由实现
一 路由原理
1. 定义
端到端的传输路径
2. url的结构
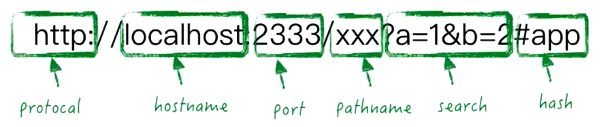
- protocal:协议头
- hostname:域名/ip/主机
- port:端口
- pathname:路径名
- search:查询参数
- hash:哈希,定位锚点,不会传输给服务器
3.浏览器查询路由信息
window.location
4. 前端路由和后端路由
后端路由:资源路径,其返回结果可能是图片、json、html等
通过用户请求的url导航到具体的html页面;每跳转到不同的URL,都是重新访问服务端,然后服务端返回页面,页面也可以是服务端获取数据,然后和模板组合,返回HTML;也可以是直接返回模板HTML,然后由前端js再去请求数据,使用前端模板和数据进行组合,生成想要的HTML
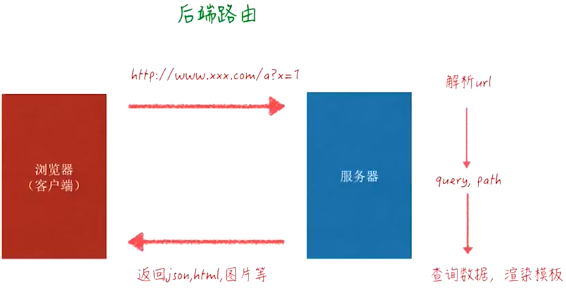
后端路由 前端路由:前端自身解析路由信息
前端单页应用 SPA(Single Page Application)中,路由描述的是 URL 与 UI 之间的映射关系,这种映射是单向的,即 URL 变化引起 UI 更新(无需刷新页面)
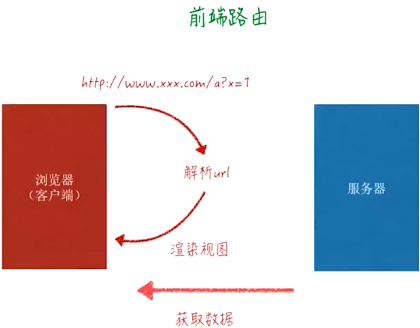
前端路由 对比
从性能和用户体验的层面来比较的话,后端路由每次访问一个新页面的时候都要向服务器发送请求,然后服务器再响应请求,这个过程肯定会有延迟。
前端路由在访问一个新页面的时候仅仅是变换了一下路径而已,没有了网络延迟,对于用户体验来说会有相当大的提升。
在某些场合中,用ajax请求,可以让页面无刷新,页面变了但Url没有变化,用户就不能复制到想要的地址,用前端路由做单页面网页就很好的解决了这个问题。但是前端路由使用浏览器的前进,后退键的时候会重新发送请求,没有合理地利用缓存。
提示
那么前端路由还有什么缺点?🤔
可以先思考 后面会解答
二 前端路由
如何实现前端路由?
要实现前端路由,需要解决两个核心问题:
提示
- 如何改变 URL 却不引起页面刷新?
- 如何检测 URL 变化了?
下面分别使用 hash 和 history 两种实现方式回答上面的两个核心问题。
hash 实现
hash 是 URL 中 hash (
#) 及后面的那部分,常用作锚点在页面内进行导航,改变 URL 中的 hash 部分不会引起页面刷新通过 hashchange 事件监听 URL 的变化,改变 URL 的方式只有这几种:通过浏览器前进后退改变 URL、通过
<a>标签改变 URL、通过window.location改变URL,这几种情况改变 URL 都会触发 hashchange 事件运作流程
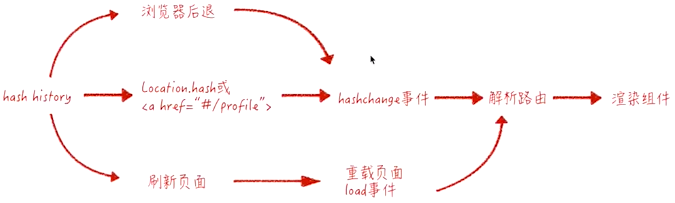
hash 运作流程 特点
- 丑
- 占用锚点功能
- 兼容性好(兼容到ie8)
history 实现
history 提供了 pushState 和 replaceState 两个方法,这两个方法改变 URL 的 path 部分不会引起页面刷新
history 提供类似 hashchange 事件的 popstate 事件,但 popstate 事件有些不同:通过浏览器前进后退改变 URL 时会触发 popstate 事件,通过
pushState/replaceState或<a>标签改变 URL 不会触发 popstate 事件。好在我们可以拦截pushState/replaceState的调用和<a>标签的点击事件来检测 URL 变化,所以监听 URL 变化可以实现,只是没有 hashchange 那么方便。运作流程
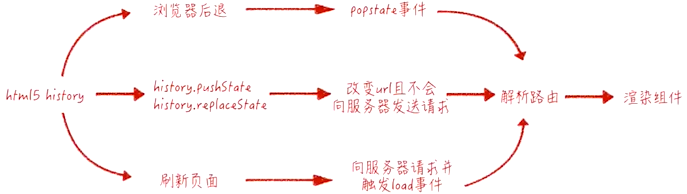
history 模式运作流程 特点
- 兼容到ie10
- 路由与后端无异,可以直接改变路径名称,而不是只能改变hash 值
- 需要后端支持,因为路由在刷新页面的时候还是会向服务器发起请求,若服务器没有相应路径,就会报404 错误
前端路由缺点及探讨解决方案
前端路由使用浏览器的前进,后退键的时候会重新发送请求,没有合理地利用缓存
当路由对应页面请求数据更新不是很频繁时,可以在首次请求时存储在浏览器(前端)或者后端接口返回数据时在Response Headers设置缓存策略 (后端)
无法记住之前滚动的位置
可以配合生命周期进行手动调整,比如离开页面(onbeforeunload)时记录页面和位置,进入时候(onload)再恢复
文件大时会出现首页白屏
- 使用加载动画/骨架屏(自我欺骗🤣)
- 懒加载,实质就是分割和此路由相关js css,访问时再加载,而不是一股脑全加载.
把组件按组分块
2.1. 使用 webpack
有时候我们想把某个路由下的所有组件都打包在同个异步块 (chunk) 中。只需要使用命名 chunk,一个特殊的注释语法来提供 chunk name (需要 Webpack > 2.4):
const UserDetails = () => import(/* webpackChunkName: "group-user" */ './> UserDetails. vue') const UserDashboard = () => import(/* webpackChunkName: "group-user" */ './> UserDashboard. vue') const UserProfileEdit = () => import(/* webpackChunkName: "group-user" */ './ > UserProfileEdit.vue')webpack 会将任何一个异步模块与相同的块名称组合到相同的异步块中。
2.2. 使用 Vite
在Vite中,你可以在
rollupOptions下定义分块:// vite.config.js export default defineConfig({ build: { rollupOptions: { // https://rollupjs.org/guide/en/#outputmanualchunks output: { manualChunks: { 'group-user': [ './src/UserDetails', './src/UserDashboard', './src/UserProfileEdit', ], }, }, }, }, })- CDN资源优化 (找个带宽好大哥😏)第三方npm包都用CND加载
- 缓存 静态资源长期不需要修改的,使用强制缓存
- SSR 服务端渲染,在服务端将渲染逻辑处理好,然后将处理好的HTML直接返回给前端展示,可以解决白屏问题。(🤑加前端部署服务器)
不利于搜索引擎的抓取 这一点仅靠前端渲染没用什么好办法,只用搜索引擎优化算法(比如Google Hash SEO),或者还是SSR(钞能力🤑)
补充SEO 基本常识
- 全称:Search Engine Optimization,搜索引擎优化。自从有了搜索引擎,SEO便诞生了。
- 存在的意义:为了提升网页在搜索引擎自然搜索结果中的收录数量以及排序位置而做的优化行为。
- 前端SEO: 通过网站的结构布局设计和网页代码优化,使前端页面既能让浏览器用户能够看懂,也能让“蜘蛛”看懂。 常用优化SEO手段
- 合理的title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可;description把页面内容高度概括,不可过分堆砌关键词;keywords列举出重要关键词。
- 语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
- 重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,保证重要内容一定会被抓取
- 重要内容不要用js输出:爬虫不会执行js获取内容
- 少用iframe:搜索引擎不会抓取iframe中的内容
- 非装饰性图片必须加alt
- 提高网站速度:网站速度是搜索引擎排序的一个重要指标。
网页SEO优化三剑客: title、description、keywords
<title>CSDN - 专业开发者社区</title> <meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播"> <meta name="description" content="CSDN是全球知名中文IT技术交流平台,创建于1999年,包含原创博客、精品问答、职业培训、技术论坛、资源下载等产品服务,提供原创、优质、完整内容的专业IT技术开发社区.">
彩蛋:🎉前端第三种路由模式?🎉
不修改 url ,路由地址在内存中,但页面刷新会重新回到首页。(vue-router:abstract/react-router:memory)
实现思路,我们可以在内存存储一个路由历史栈进行记录路由信息
应用场景 跨端开放,非浏览器应用
附录: 原生JS版前端路由实现
基于上节讨论的两种实现方式,分别实现 hash 版本和 history 版本的路由,示例使用原生 HTML/JS 实现,不依赖任何框架。
基于 hash 实现
<body>
<h3>Hash 版</h3>
<ul>
<!-- 定义路由 -->
<li><a href="#/home">home</a></li>
<li><a href="#/about">about</a></li>
<!-- 渲染路由对应的 UI -->
<div id="routeView"></div>
</ul>
</body>//页面加载完不会触发 hashchange,这里主动触发一次 hashchange 事件
window.addEventListener('DOMContentLoaded', onLoad)
// 监听路由变化
window.addEventListener('hashchange', onHashChange)
// 路由视图
let routerView = null
function onLoad () {
routerView = document.querySelector('#routeView')
onHashChange()
}
// 路由变化时,根据路由渲染对应 UI
function onHashChange () {
switch (location.hash) {
case '':
location.hash = '#/home'
break
case '#/home':
routerView.innerHTML = '这里是 Home'
break
case '#/about':
routerView.innerHTML = '这里是 About'
break
default:
routerView.innerHTML = '这里是 一个不存在404页面'
break
}
}基于 history 实现
<body>
<h3>history 版</h3>
<ul>
<li><a href='/home'>home</a></li>
<li><a href='/about'>about</a></li>
<div id="routeView"></div>
</ul>
</body>// 监听路由变化(监听到history.go、forward、back的切换)
window.addEventListener('popstate', onPopState)
//监听路由变化(监听a链接跳转)
// 重写pushState方法
const rawPushState = window.history.pushState
window.history.pushState = function (...args) {
onPopState()
rawPushState.apply(window.history, args)
}
// 重写replaceState方法
const rawReplaceState = window.history.replaceState
window.history.replaceState = function (...args) {
onPopState()
rawReplaceState.apply(window.history, args)
}
// 路由视图
let routerView = null
function onLoad () {
routerView = document.querySelector('#routeView')
onPopState()
// 拦截 <a> 标签点击事件默认行为, 点击时使用 pushState 修> 改 URL并更新手动 UI,从而实现点击链接更新 URL UI 的效果。
const linkList = document.querySelectorAll('a[href]')
linkList.forEach(el => el.addEventListener('click', > function (e) {
e.preventDefault()
history.pushState(null, 'title', el.getAttribute('href'))
}))
}
// 路由变化时,根据路由渲染对应 UI
function onPopState () {
switch (location.pathname) {
case '/home':
routerView.innerHTML = 'Home'
break
case '/about':
routerView.innerHTML = 'About'
break
default:
routerView.innerHTML = '404'
break
}
}