编写python爬虫用到一些实用chrome拓展和工具
1.chrom拓展
1.1 Chrome Regex Search
方便你快速利用正则表达式查找网页中元素,也可以检查自己正则表达式是否书写错误。 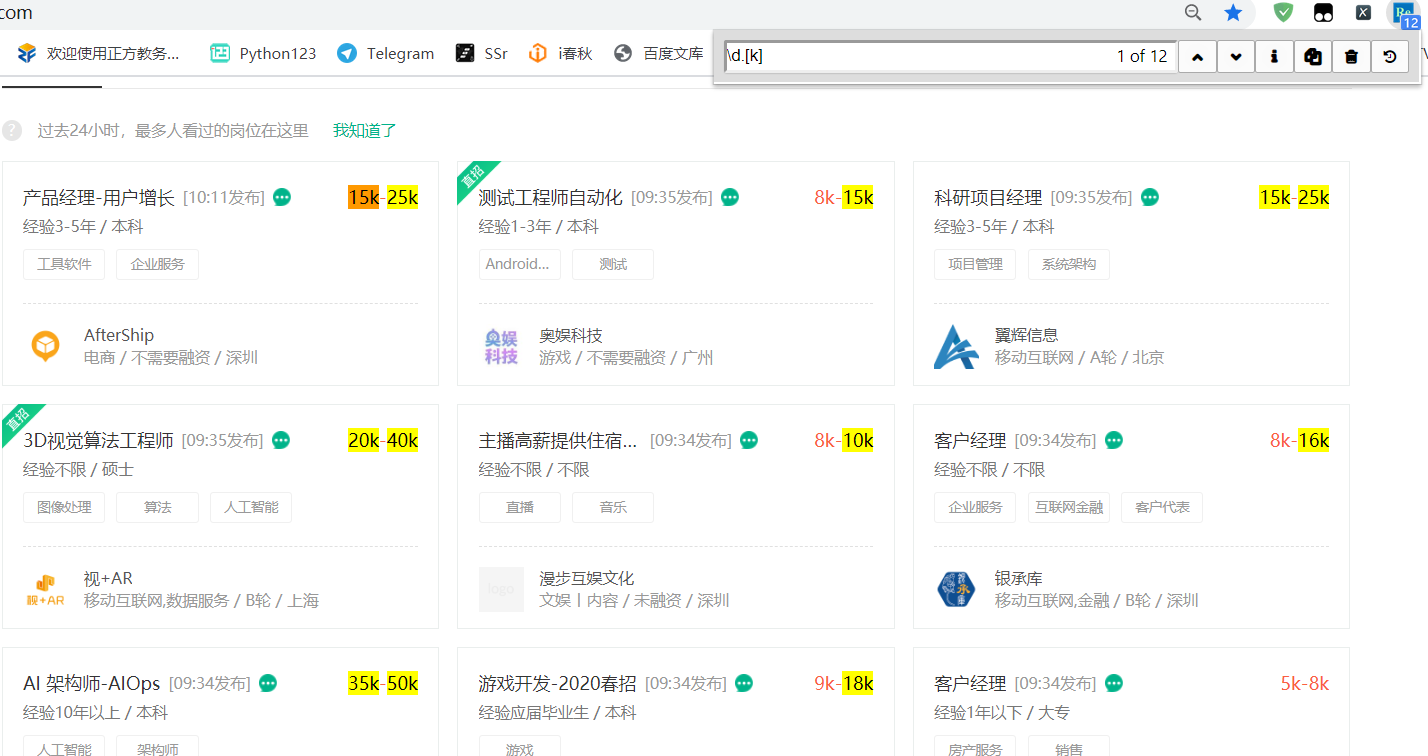
1.2 JSON-handle
格式化json信息,并且鼠标指到指定元素时有path 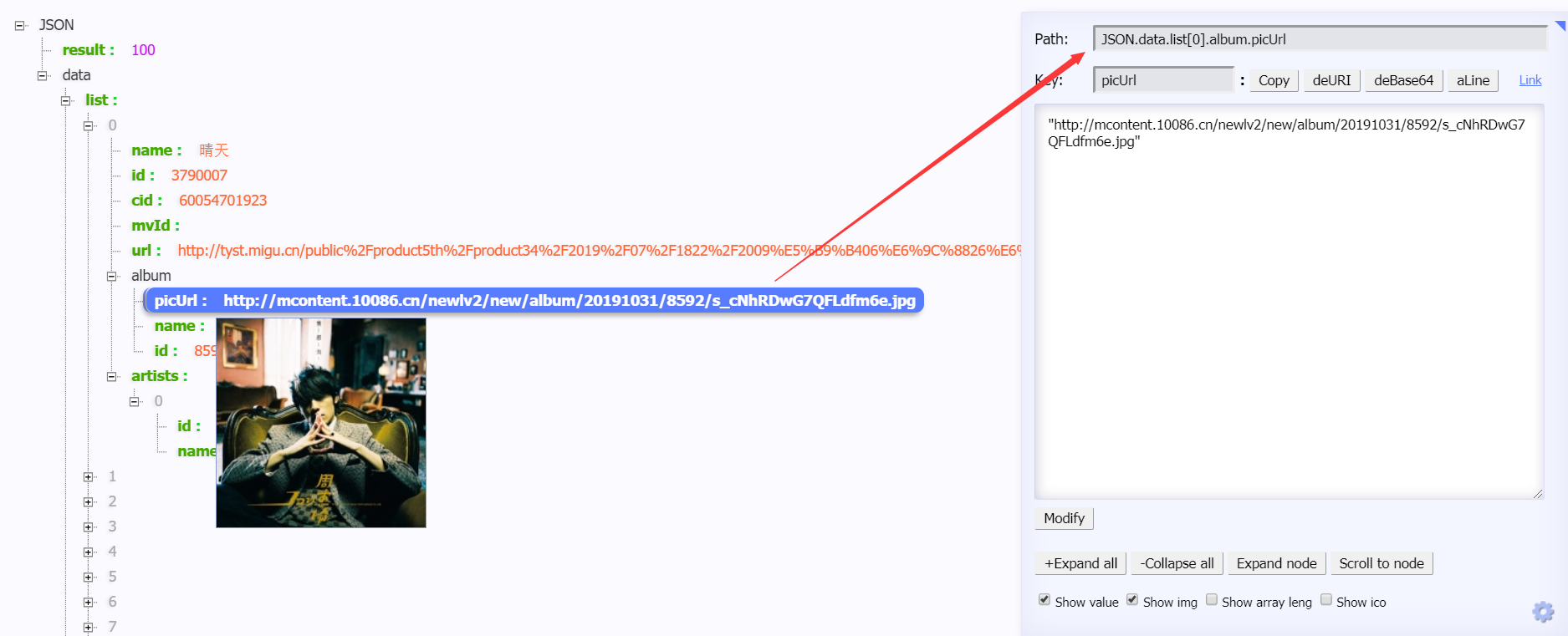
1.3 Toggle JavaScript
关闭网页中所有JavaScript动态加载,方便查找元素和检查是否为动态加载
1.4 XPath Helper
查找验证网页中xpath路径,标注出结果 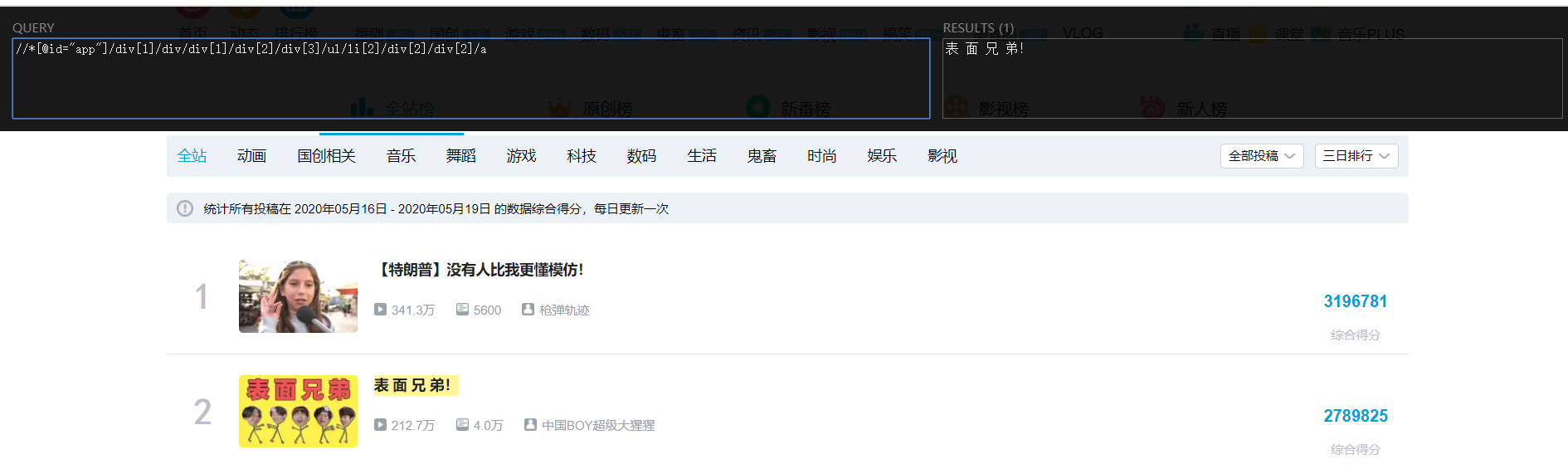
2.网站类
在我写一个爬虫时,提交post请求时,所传参数都是正确的就是得不到返回结果(后来发现时一个字符打错了),询问大佬后才知道可以利用chrome开发者工具复制下curl的代码最后转python代码这样就不会出错了,而且避免反复造轮子浪费时间。
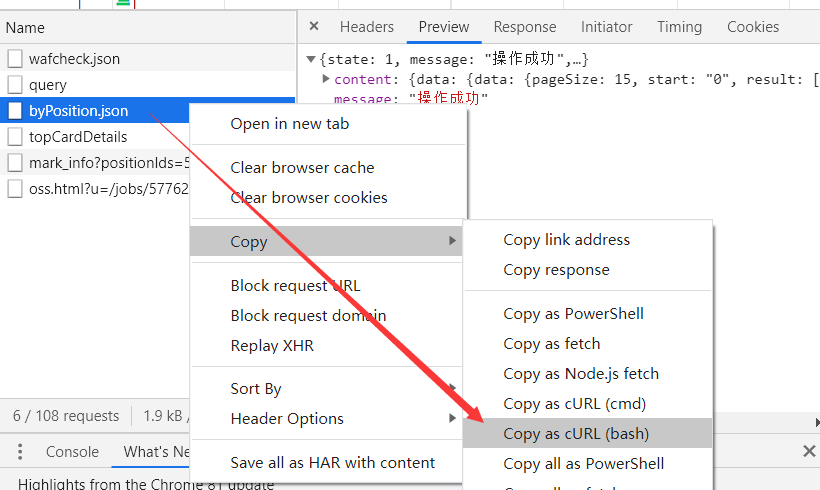 copy完后可以去终端验证下,发现没问题
copy完后可以去终端验证下,发现没问题 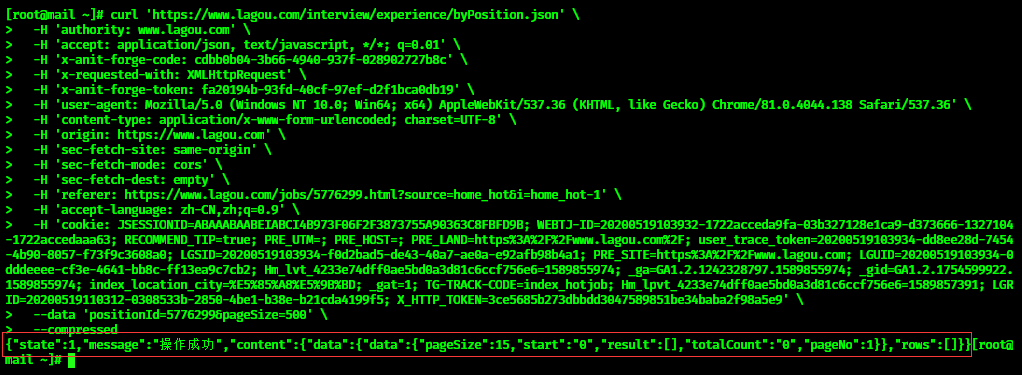 最后再利用工具网站直接转换就可以了
最后再利用工具网站直接转换就可以了 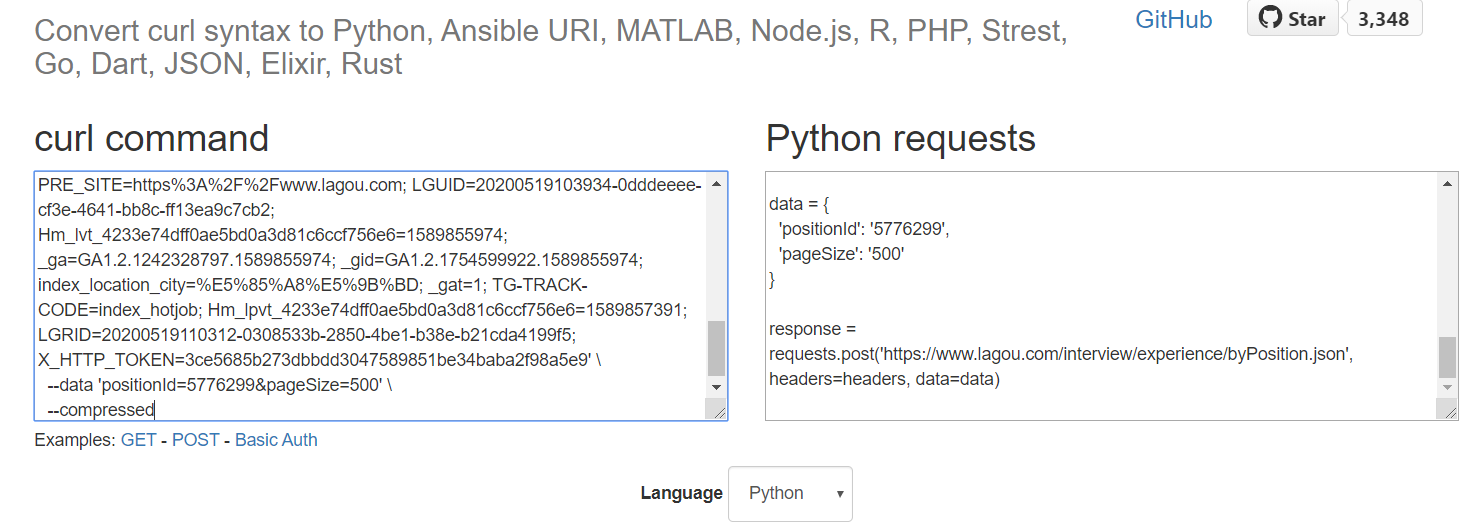
https://curlconverter.com/ 将curl语法转换为Python,Ansible URI,MATLAB,Node.js,R,PHP,Strest,Go,Dart,JSON,Elixir,Rust
下面记录下这两天遇到知识盲区:
常用三种提取数据方式的对比:
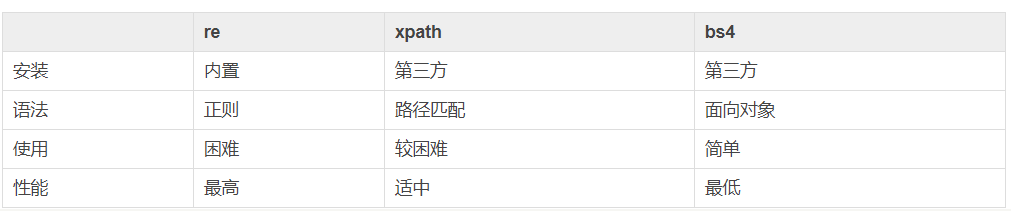 后来才发现xpath比bs4来的快。
后来才发现xpath比bs4来的快。
除了用将json格式数据解码为python对象 json转dict外,jsonpath和Xpath异曲同工之处,都是通过路径查找好像更简洁些。 通过网上示例来练习JSONPath表达式。我们从一个表示书店(原始XML文件)的XML示例之后构建的简单JSON结构开始。
{ “store”:{
“book”:[
{ “category”:“reference”,
“author”:“Nigel Rees”,
“title”:“世纪的谚语”,
“价格”:8.95
},
{ “类别”:“小说”,
“作者”:“伊夫林沃”,
“标题”:“荣誉之剑”,
“价格”:12.99
},
{ “类别”:“小说”,
“作者”:“Herman Melville”,
“title”:“Moby Dick”,
“isbn”:“0-553-21311-3”,
“price”:8.99
},
{ “类别”:“小说”,
“作者”:“JRR托尔金”,
“标题”:“指环王”,
“isbn”:“0-395-19395-8”,
“价格”:22.99
}
]
“自行车”:{
“颜色”:“红色”,
“价格”:19.95
}
}
}
