爬取了中国大学mooc平台7万多用户学习情况发现
警告
经过使用我代码复现用户反馈 此方案已失效
仅供学习使用
一直都有一个想法想看看疫情期间大家在网课平台学习情况,刚好这次python结课作业是写一个网络爬虫,
所以就对我用的比较多平台mooc中国大学下手了,在此感谢mooc平台嵩天老师python系列课程很好基础课,老师讲的很细,学完收获良多

分享结果
首先分享下爬取数据结果,后面再梳理下我的思路,第一次写python爬虫,有不对地方还希望指出,大家一起共同进步.
- 以下数据为mooc平台中截止2020年5月16日抓取7万多用户学习情况,
- 但是由于爬取数据不到总的数据10%且只爬取一次,可能不具有权威性,大家看看就好,
- 有兴趣可以自己爬爬看,文章后面会附上最初代码。
1.1 mooc平台最近学习课程关键词(词云展示)

相关信息
从关键词可以看出mooc平台用户最近学习编程人还是挺多的,特别是Python,突然感到我这个就业竞争压力还是很大的.除此之外学习工科学生要多于文科的外,学习英语,数学人也不少。让我感到奇怪是心理学怎么那么多,我猜可能很多学校选修网课都选了这个课吧。
1.2 mooc平台所有课程关键词(词云展示)

相关信息
从所有选课关键词中可以看出,公共必修课还算占了很大份额,其他和最近所学课程差不多,都是工科偏多,计算机专业还是很突出,这个专业有这么热门么?
1.3 学习时长排行榜(仅以我抓取7万数据处理,不代表整体,单位:min)

相关信息
虽然我只爬取7万多数据,但是由于是分段爬取的,应该还是能说明一些问题,越靠前学习时长跨度越大,越靠后大家数据跟着越紧。 第一名同学居然学习998门课程,9783小时学习时间,相当于没日没夜学407天,真的强附上大佬空间图片:
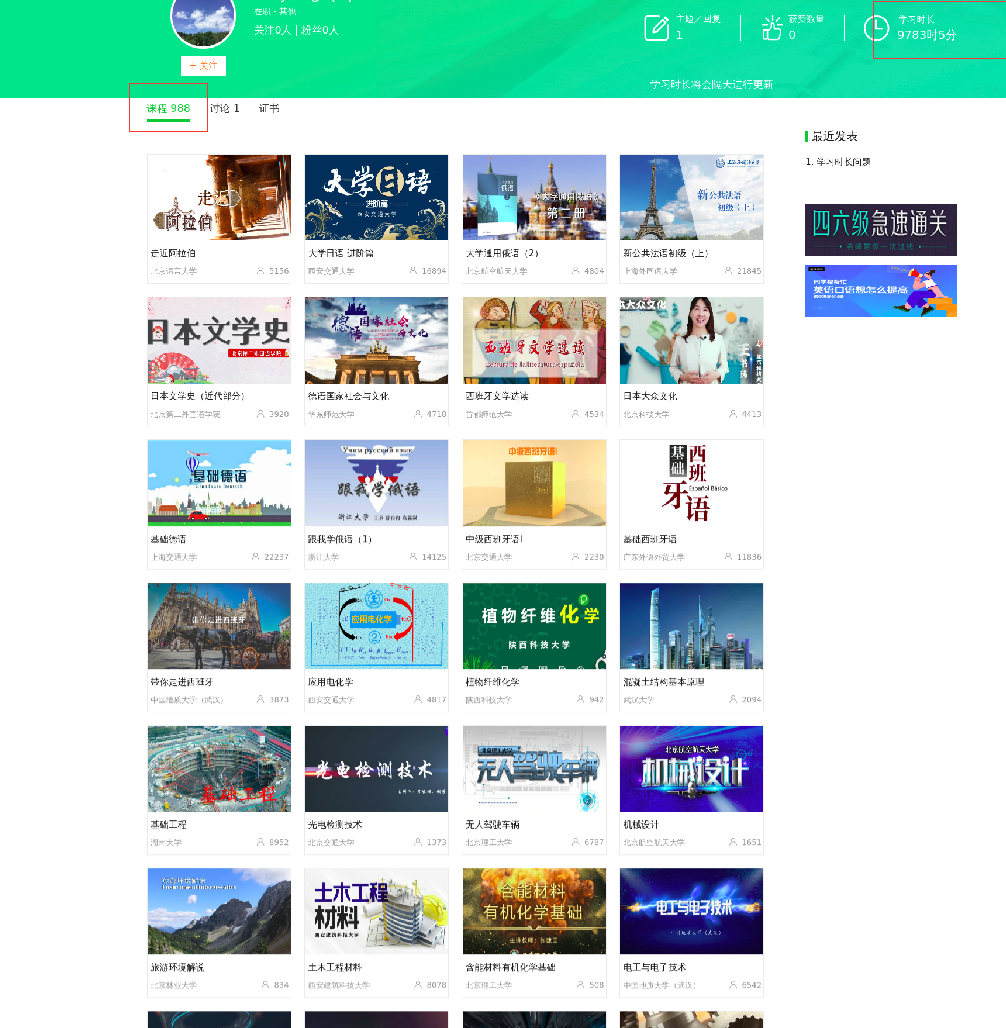
提示
4470分钟的我连第一名零头都凑不到.
关键我还在排行榜发现我们班上一位低调大佬,第29名那名同学居然是我们班上的,我是不是该反思下自己。
那位同学是大二时候其他专业转过来的,原来他一直在偷偷充电,怪不得后来进步那么快。
1.4 学习时长分段图
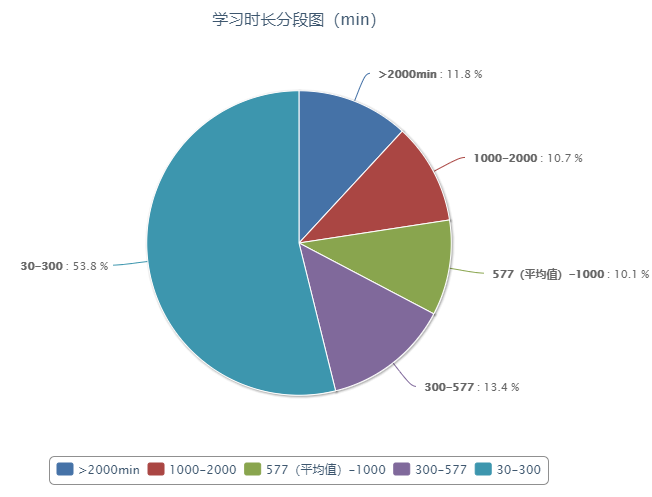
相关信息
这里我只提取30分钟以上数据,通过观察可以看出mooc平台学习时长少于5小时账号还是挺多的,占了一半多,有32.6%在平均值以上 但是大佬们也不少,在>2000分钟里面其实区别还是很大的,从排行榜可以看出,通过怎样合理取区间是我数学上失误 由于这些是我自己计算统计的,而且获取用户数据有限,可能存在一定问题,大家看看就好,不必太较真。
代码思路
2.以下就是代码部分思考了
注意
在这篇博客写出来之前,我向网易提交mooc能够轻易获取到用户学习情况,得到该信息是业务上可公开的,没风险,第一天给我回复是已经确认是漏洞,第二天又说是误报,误报就误报吧,我也可以安心写我的博客了!
2.1 写代码前我还是看了mooc平台robots协议
但是它的robots协议写的实在不伦不类,既没有指出禁止运行,就留一个站点, 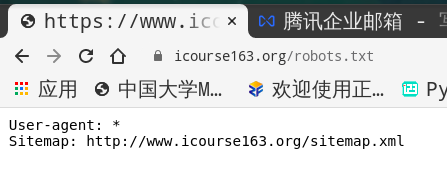
看到站点我还是不放心去检索下: 
确认爬取站点不在内我才安心!
2.2 爬取前分析
在我还未学习python这门课之前我就发现平台一个问题,当我的cookis失效情况下(相当于没登录情况下)我打开自己个人空间,看到自己信息,
我尝试手动修改Id也可以访问别人空间,我就猜测这个页面不需要验证就可以访问。

后面准备写爬虫时候我却发现也没那么简单,当我关闭js加载后:

我需要数据全不见了
那这个页面部分数据就是动态加载生成的,遇到这个问题我知道就两种方法,
- selenium模拟浏览器抓取,
- 抓包分析直接抓接口.
提示
前者抓取速度慢,但是操作简单,后者找接口麻烦一点,但是后期抓取快直接返回想要数据.
我便是用的第二种方法。这里抓包过程就不累述了
直接上接口链接,全部以我的信息为例:
返回用户头像,昵称等信息 https://www.icourse163.org/web/j/memberBean.getMocMemberPersonalDtoById.rpc
{'code': 0, 'result': {'memberId': 'xxxxxxxxx', 'schoolName': '其他', 'schoolId': None, 'nickName': '游尚忘烦', 'largeFaceUrl': 'https://img-ph-mirror.nosdn.127.net/y-3-D05OabXYiLo3y6G00w==/6632377284050677150.jpg', 'department': '其他', 'memberType': 1, 'highestDegree': 5, 'jobName': None, 'description': None, 'richDescription': None, 'lectorTitle': None, 'realName': None, 'isTeacher': False, 'followCount': 3, 'followedCount': 0, 'schoolShortName': None, 'logoForCertUrl': None, 'supportMooc': None, 'supportSpoc': None, 'followStatus': False, 'supportCommonMooc': None, 'supportPostgradexam': None, 'lectorTag': None, 'relType': None}, 'message': '', 'traceId': '', 'sampled': False}返回平台参与度信息,包含我需要学习时长 https://www.icourse163.org/web/j/MocActivityScholarshipRpcBean.getActivityStatisticsByUser.rpc
{'code': 0, 'result': {'isSign': None, 'statistics': {'signCount': 0, 'courseCount': 0, 'postCount': 1, 'voteCount': 0, 'replyCount': 7, 'commentCount': 0, 'learnLongTimeCount': 4470}}, 'message': '', 'traceId': '', 'sampled': False}返回所学习课程信息,最近学习靠前(这个我的返回太多了,找了个短做例子) https://www.icourse163.org/web/j/learnerCourseRpcBean.getOtherLearnedCoursePagination.rpc
{'code': 0, 'result': {'query': {'sortCriterial': None, 'DEFAULT_PAGE_SIZE': 10, 'DEFAULT_PAGE_INDEX': 1, 'DEFAULT_TOTLE_PAGE_COUNT': 1, 'DEFAULT_TOTLE_COUNT': 0, 'DEFAULT_OFFSET': 0, 'pageSize': 32, 'pageIndex': 1, 'totlePageCount': 1, 'totleCount': 1, 'offset': 0, 'limit': 32}, 'list': [{'uid': 1032127356, 'courseCoverUrl': 'http://edu-image.nosdn.127.net/65B575B91765DBCD593C825AB376F329.jpeg?imageView&thumbnail=426y240&quality=100', 'courseId': 53004, 'courseProductType': 1, 'courseName': '高等数学(一)', 'enrollCount': 109782, 'schoolName': '同济大学', 'schoolId': 8013, 'schoolShortName': 'TONGJI', 'whatCertGot': None, 'termId': 50003, 'supportCommonMooc': None, 'mode': 0, 'termPrice': None, 'termOriginalPrice': None}]}, 'message': '', 'traceId': '', 'sampled': False}经过仔细观察找到接口,接口传参是以post形式提交请求返回参数的
注意
提交过程中params中的csrfKey和浏览器cookie中NTESSTUDYSI以及请求地址末尾参数做校验
所以只要csrfkey中数值和NTESSTUDYSI一样就行,随便你填什么,只要是字符串
最让我惊喜的是返回数据是json格式的,bs4解析都不用了。
所以数据提取变得很简单了。这里以提取学习时长为例:
首先将json转dict类型,然后利用键逐级取值
nickName=json_data['result']['nickName']#昵称
largeFaceUrl=json_data['result']['largeFaceUrl']#头像或者利用jsonpath路径直接提取也很不错(这里如何使用jsonpath,上一篇博客有笔记例子)
#nickName=jsonpath(json_data,"$..nickName")#昵称
#largeFaceUrl=jsonpath(json_data,"$..largeFaceUrl")#头像2.3批量爬取
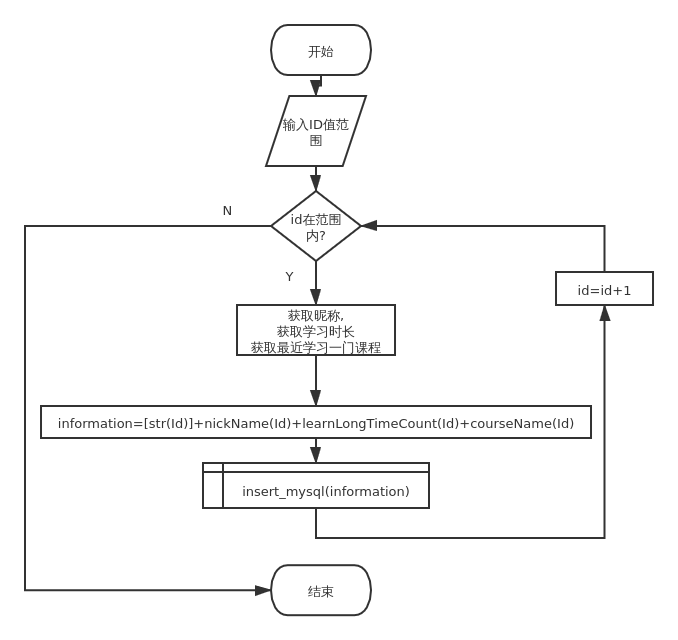
经过前面大量分析我发现其实我要写的代码量好像并不是很多.用户id问题,经过我发现是个10位数而且新用户数值大老用户数值小,通过高位逐个递减到返回数据为空发现最小id为:1015002001
由于平台一直在注册后面新用户数据统计没意义,我便取我新注册用户id为最大值1437038940 这里我写了4个函数:
def nickName(Id):#获取用户昵称
def learnLongTimeCount(Id):#获取学习时长
def courseName(Id):#获取用户所选课程
def insert_mysql(data):#将数据存入MySQL由于准备在服务器中跑很长时间,后期加入异常处理,以及无用数据判断剔除 但基本流程图在上方画出.
有个这个思路便写出下面最原始代码:
import requests
import json
#全局公用信息
csrfKey='None'#随便什么都行但必须有
params = (
('csrfKey', csrfKey),
)
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
'cookie': 'NTESSTUDYSI=None',
}
#获取昵称,图像
def nickName(Id):
memberId=Id
data = {
'memberId': memberId
}
url='https://www.icourse163.org/web/j/memberBean.getMocMemberPersonalDtoById.rpc'
response = requests.post(url, headers=headers, params=params, data=data)
datas=response.text#获得json信息
json_data=json.loads(datas)#将返回json信息转化为字典类型
nickName=json_data['result']['nickName']#昵称
largeFaceUrl=json_data['result']['largeFaceUrl']#头像
return nickName,largeFaceUrl
#获取学习时长
def learnLongTimeCount(Id):
memberId=Id
data = {
'userId': memberId
}
url='https://www.icourse163.org/web/j/MocActivityScholarshipRpcBean.getActivityStatisticsByUser.rpc?csrfKey='+csrfKey
response = requests.post(url, headers=headers, params=params, data=data)
datas=response.text
json_data=json.loads(datas)
learnLongTimeCount=json_data['result']['statistics']['learnLongTimeCount']
return learnLongTimeCount
#获取所选课程返回一个字符串列表
def courseName(Id):
memberId=Id
url='https://www.icourse163.org/web/j/learnerCourseRpcBean.getOtherLearnedCoursePagination.rpc'
data = {
'uid': memberId,
'pageIndex': '1',
'pageSize': '32'
}
response = requests.post(url, headers=headers, params=params, data=data)
datas=response.text
json_data=json.loads(datas)
n=len(json_data['result']['list'])
courseName=[]
if(n==0):
return'没选课'
else:
for i in range (n):
courseName+=[(json_data['result']['list'][i]['courseName'])]
return json_data
def main():
#ID最小值为1017120000
#下面为任意展示
Id=1032127355
for i in range(Id,1032127999):
print("用户id:{}\n|昵称+头像|:\n|{}|→|学习时长{}分钟|\n所选课程↓\n{}".format(Id,nickName(Id),learnLongTimeCount(Id), courseName(Id)))
print("=" * 100)
Id=Id+1
main()遇到一些问题
数据量太大 经过我简单计算我发现单凭这一个python程序肯定爬不完,而且也没必要爬那么多,于是我把id分成10段爬取
用户多课程输入问题
本来我是准备把爬取下来数据全部存一个表的,但是用户课程数量不确定, 我的表头确是确定的,最后我用了两张表,
- 一张记录昵称,学习时长,最近学的一门课程,
- 另外一张表专门记录所有课程
为了使平台影响最小我选择晚上爬取,此时访问人数少最不易造成网络拥堵.
为了能在服务器上跑,我做了简单异常处理和数据筛选功能,排除选课为None和学习时长为0用户,
处理写的很简陋,存在很大优化地方当时为了赶时间爬数据交作业很多地方没有深究,现在看看代码真的有点烂,用很多可以改进地方。
服务器爬取版本
import requests
import json
from jsonpath import jsonpath
import pymysql
#全局公用信息
csrfKey='text'#随便什么都行,但必须有
params = (
('csrfKey', csrfKey),
)
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
'cookie': 'NTESSTUDYSI=text',
}
conn = pymysql.connect(host='localhost', user='root', password='xxxxxxx',
database='m163', port=3306, charset='utf8')
# 创建游标
cursor = conn.cursor()
def insert_mysql(data):
cursor.execute(
'insert into information(id,nickname,time,latelystudy) VALUES("%s","%s","%s","%s")' % (
data[0],data[1],data[2],data[3]))
# 从游标中获取结果
cursor.fetchall()
# 提交结果
conn.commit()
#获取昵称
def nickName(Id):
memberId=Id
data = {
'memberId': memberId
}
url='https://www.icourse163.org/web/j/memberBean.getMocMemberPersonalDtoById.rpc'
response = requests.post(url, headers=headers, params=params, data=data)
datas=response.text
json_data=json.loads(datas)
nickName=jsonpath(json_data,"$..nickName")
return nickName
#获取学习时长
def learnLongTimeCount(Id):
memberId=Id
data = {
'userId': memberId
}
url='https://www.icourse163.org/web/j/MocActivityScholarshipRpcBean.getActivityStatisticsByUser.rpc?csrfKey='+csrfKey
response = requests.post(url, headers=headers, params=params, data=data)
datas=response.text
json_data=json.loads(datas)
learnLongTimeCount=jsonpath(json_data,"$..learnLongTimeCount")
if(learnLongTimeCount[0]==0):#学习时长为0,直接返回数字0异常爬取下一个
return 0
return learnLongTimeCount
#获取课程
def courseName(Id):
memberId=Id
url='https://www.icourse163.org/web/j/learnerCourseRpcBean.getOtherLearnedCoursePagination.rpc'
data = {
'uid': memberId,
'pageIndex': '1',
'pageSize': '32'
}
response = requests.post(url, headers=headers, params=params, data=data)
datas=response.text
json_data=json.loads(datas)
n=jsonpath(json_data,"$..totleCount")
if(n[0]==0):#没有课程,返回数字0异常,爬取下一个
return 0
courseName=jsonpath(json_data,"$..courseName")
return [courseName[0]]
def main():
Id=1032127300
while(Id<1032127400):
try:
#得到一个字符串列表用于存储信息
information=[str(Id)]+nickName(Id)+learnLongTimeCount(Id)+courseName(Id)
#print(information)
insert_mysql(information)
Id=Id+1
except:
Id=Id+1
# 关闭游标
cursor.close()
# 关闭数据库
conn.close()
main()虽然爬取效率不算高,但是稳定性还算不错,爬取差不多12多个小时没有终止异常退出,爬取7万多条非空数据
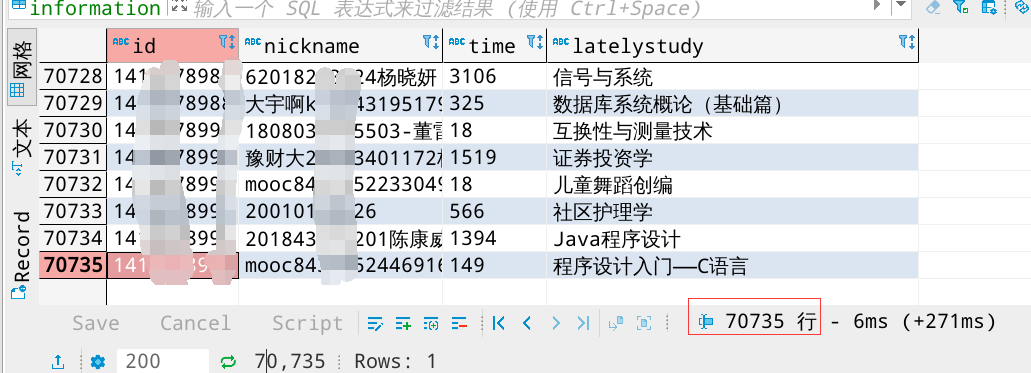
我的词云是在用户所选课程经过jieba库词频分析在wordcloud输出
关于如何生成一个漂亮词云,大佬有详细介绍我也是参考大佬代码就不写了
代码能够优化地方还有很多,如引入多进程,使用多个代理,优化存储,数据筛选闸值,数据可视化。有更好方法也欢迎交流学习,代码上有疑问也欢迎探讨,第一次写python爬虫时间也有点赶,有不对地方也欢迎指出共同进步
最后分享几个小技巧: 如何让python程序一直在后台运行(linux):
nohup python xxx.py &终止运行python进程(linux)
- 先查询出后台运行进程号:
ps -ef | grep python - 最后
kill xxxx
在当前目录打开cmd(win) 直接在目录内上方文件框打入cmd回车即可
